Cet article aurait dû voir le jour plus tôt, en effet je pensais le consacrer au sujet du dernier Meetup Hug France qui a eu lieu le 30 juin 2014 ! Je vais profiter de cet article pour vous faire part des actualités au sujet des technologies Big Data chez Microsoft 😉
Retour sur le Meetup Hug

Le Lundi 30 juin 2014 à u lieu au centre de conférences de Microsoft un Meetup organisé par la communauté des utilisateurs Hadoop Francophones : HUG France.
Pour ceux qui ne connaissent pas encore Meetup, c’est un réseau social en ligne facilitant la création du groupe communautaire autour d’un intérêt commun, tel que la politique, la lecture, les techniques ou encore les loisirs. Les utilisateurs entrent leur ville et les sujets qui les intéressent, le site leur propose alors un certain nombre de groupes existants auquel ils pourront adhérer.
Quelques ressources du groupe HUG France :
- Les présentations Slideshare
- Les vidéos Vimeo
- Le Google Group https://groups.google.com/forum/#!forum/hadoop-user-group-france
- Le Twitter @hugfrance
Mise en place de Hive chez Square :
Nicolas Thiébaud (a l’origine du HUG France) nous a fait un retour sur la mise en place de HIVE chez Square.
 Square est une entreprise spécialisée dans le paiement mobile et le paiement électronique. Elle est basée à San Francisco et a été fondée en 2009 par Jack Dorsey (fondateur du réseau social Twitter) et Jim McKelvey.
Square est une entreprise spécialisée dans le paiement mobile et le paiement électronique. Elle est basée à San Francisco et a été fondée en 2009 par Jack Dorsey (fondateur du réseau social Twitter) et Jim McKelvey.
Square a énormément misé sur Hive et ils ont rencontré pas mal de problèmes leur retour est donc très intéressant. Ils ont décidé de Forker, Patcher Hive pour qu’il puisse répondre à leurs besoins.
Leur projet de migration d’une base MySQL à Hive s’appelle « Babar ». Je vous invite à revoir la présentation à cette adresse : Brainsonic
Les nouveautés de Hive coté performance :
Eric Hanson nous a présenté les quelques nouveautés de Hive permettant d’améliorer grandement les performances :
-
ORC : Le format de fichier Optimized Row Columnar (ORC) permet un stockage des données Hive en colonne et améliore ainsi les performances en lecture, écriture, et en traitement ! Un fichier ORC se décompose d’un ensemble de lignes appelées Stripes (250Mb par défaut). Un fichier ORC a un pied de page qui contient la liste des emplacements des Stripes et des informations comme le Count, le Min, le Max, et le Sum de ses données. Voici comment l’activer dans Hive:
CREATE TABLE tablename ( ... ) AS ORC;
ou
ALTER TABLE tablename SET FILEFORMAT ORC;

-
TEZ simplifie le processing des données en généralisant le modèle de programmation Map Reduce dans une seule Job :
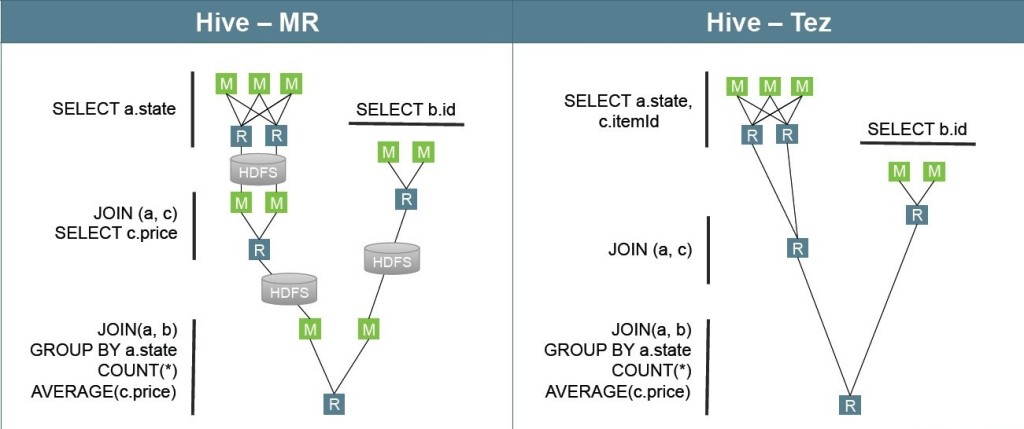
Voici comment l’activer dans Hive:
set hive.use.tez.natively=true; set hive.enable.mrr=true;
-
VECTORIZATION permet à Hive de traiter en mode batch un certain nombre de lignes. Pour profiter de vectorisation, votre table doit être au format ORC. Pour activer vectorisation avec la propriété suivante :
hive.vectorized.execution.enabled = true
Remarque : Lorsque la Vectorization est activée, Hive va examiner la requête et les données pour déterminer si la Vectorization est possible ou non, ce qui activera ou nom l’option.

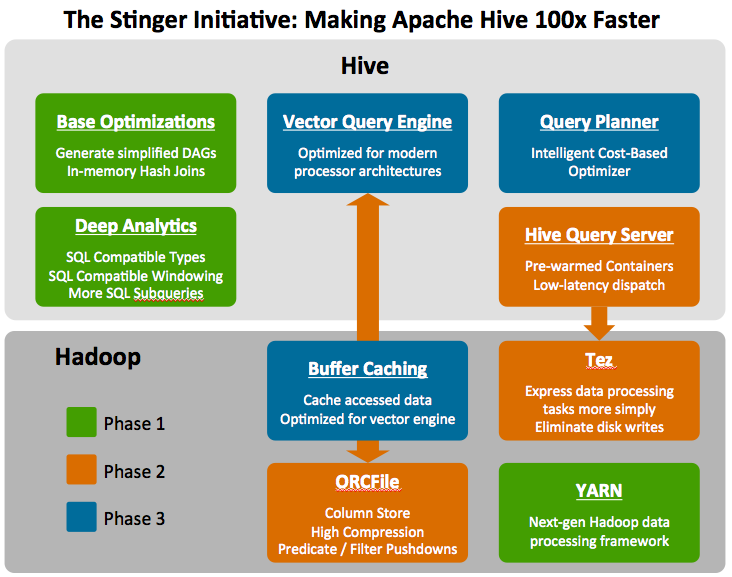
Voici les différentes phases de l’initiative Stinger :
Nous préparons avec mes collègues des BigDataMonkeys un Benchmark de ces options optimisant le traitement de données dans Hadoop !

HDInsight – HBase
Concernant les nouveautés de HDInsight, la version par défaut est désormais la 3.1. Elle se base sur HDP 2.1 qui se base sur la version Hadoop 2.4.
Noté le changement de logo de HDInsight dans Azure 😉
Voici une liste des nouveautés, que j’avais commencé à décrire dans l’article HBASE – HDINSIGHT 3.1 :
- Cluster Dashboard
- Microsoft Avro Library
- Mahout
- HBase (Preview)
- YARN
- TEZ
- High Availability
- Hive performance


Comments are closed.