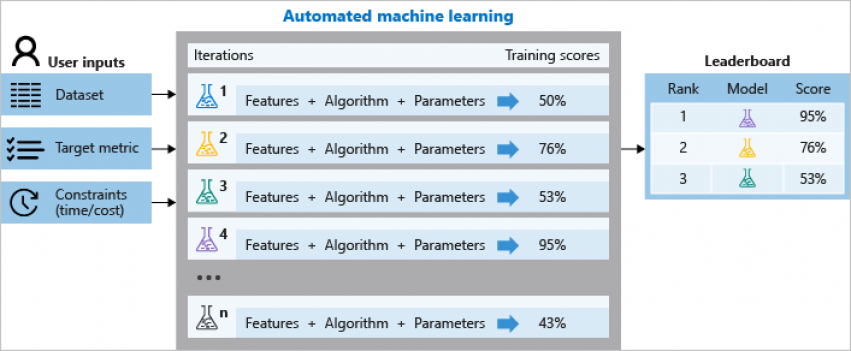
L’apprentissage automatique, également appelé AutoML, permet de simplifier la génération de modèles de Machine Learning. En construisant plusieurs versions de modèles et en comparant leurs qualités Azure Machine Learning service permet de choisir celui le plus adéquate pour une mise en production rapide.

Dans cet article nous présenterons le service Automated Machine Learning et nous verrons les avantages de son usage au sein des bases de données. Pour cela, nous utiliserons un problème de classification déjà utilisé dans quelques-uns de mes articles sur l’analyse de la qualité de vins :
– Azure Machine Learning Studio & Wine Quality : FR | EN
– SQL Server Machine Learning Services & Wine Quality : FR | EN
1 – Introduction
Prenons un exemple typique de la manière dont nous construisons un modèle ML aujourd’hui : Nous regroupons différentes sources de données, nous les préparons, nous entrainons un modèle et une fois satisfait de la sortie du modèle nous déployons celui-ci.
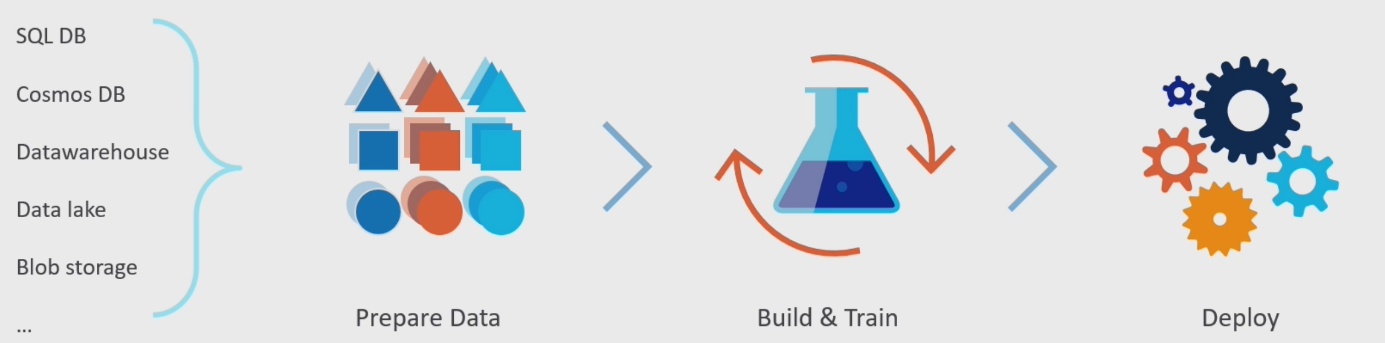
Ces différentes étapes supposent de multiples prises de décisions interconnectées, la transformation et l’enrichissement des données, l’entrainement du modèle en fonction de métrique d’optimisation sélectionnée, réglage et optimisation des hyperparamètres, autant pour les transformateurs de données que les algorithmes ML, …


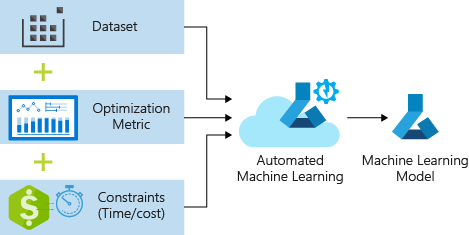
Le service Azure Machine Learning et sa fonctionnalité d’AutoML répond exactement à cette problématique et permet d’éviter ces étapes itératives et de maximiser la qualité du modèle finale à partir des objectifs et des contraintes que vous définissez.
Mais quel est le lien avec SQL Server ?
– Dans SQL Server 2016, il est possible d’installer R Services, un module complémentaire à une instance de moteur de base de données utilisé pour l’exécution de code R et des fonctions sur SQL Server.
– Dans SQL Server 2017, le R Services a été renommé en SQL Server Machine Learning Services, reflétant l’ajout du langage Python.
– Dans SQL Server 2019 (actuellement en Preview), le langage Java est ajouté aux langages R et Python ainsi que le support sur Linux et de hautes disponibilités (FCI), le support des données partitionnées…
Cela tombe bien, la fonctionnalité d’AutoML dans le service Azure Machine Learning est accessible en Python ! Nous allons donc pouvoir depuis SQL Server demander l’entrainement de modèle ML et sauvegarder le meilleur d’entre eux en base de données afin de l’utiliser localement.
2 – Automated Machine Learning
Dans cette section, on vous présente un aperçu de l’approche proposée par AutoML qui a été publié dans l‘étude « Probabilistic Matrix Factorization for Automated Machine Learning » et que nous vous invitons à étudier pour de plus amples détails.
Comme on a pu l’évoquer précédemment, AutoML a pour vocation d’automatiser la sélection et le réglage du meilleur pipeline ML qui combine prétraitement, sélection d’algorithmes et optimisation, l’objectif à minimiser est donc :
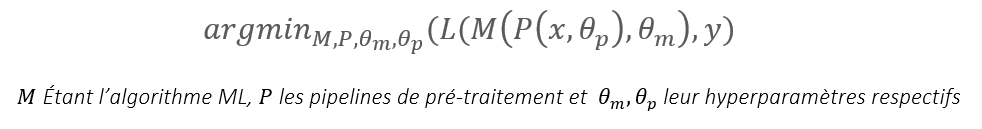
Voici un résumé intuitif des étapes entreprises par AutoML :
1. AutoML instancie des pipelines en avance et procède à un échantillonnage, ce qui permet une discrétisation de l’espace des hyperparamètres des pipelines, un espace qui forme une combinaison de variables discrètes et continues.
2. Ensuite AutoML procède à l’entrainement de N pipelines sur D jeu de données de référence, constituant ainsi une matrice creuse Y∈R^NxD qui résume la performance de chaque pipeline échantillonné.
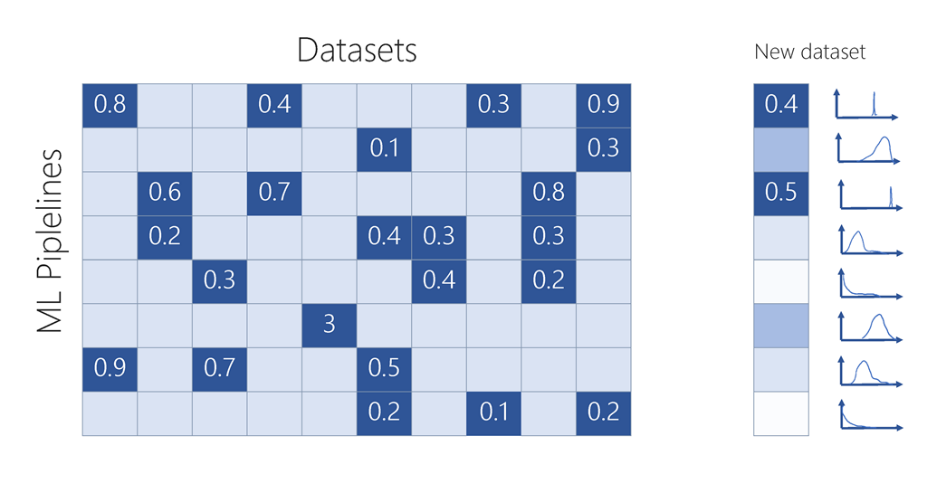
3. Vous l’aurez donc compris, l’objectif est de compléter la matrice Y, l’idée derrière l’approche, si deux jeux de données produisent un résultat similaire pour quelques pipelines, il est probable que le reste des pipelines produiront des résultats similaires. Tel est le rôle de cette étape, apprendre un modèle latent à base de factorisation de matrices probabilistes (PMF). Le PMF est essentiellement un processus gaussien à base de modèles latents (GP-LVM).
Le GP-LVM est une méthode non-supervisée qui consiste à apprendre un espace latent X à dimension réduite et non-linéaire à partir d’un espace d’observation Y. On pourra aussi le décrire comme étant un ACP intégré dans un processus gaussien (PG).
On suppose donc que les éléments de sont des valeurs d’une fonction bruitée non-linéaire des variables latents avec un bruit additif gaussien et de moyenne nulle.
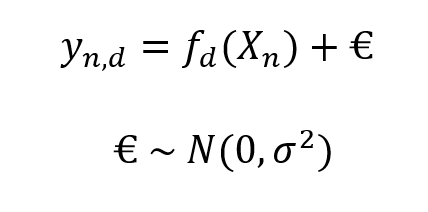
Ainsi la vraisemblance suivante en découle :
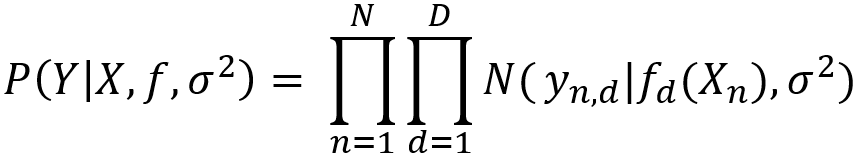
Ensuite, un prior gaussien est placé sur f_d (X_n ) ce qui donne :
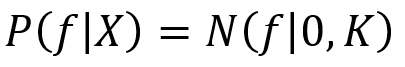
où K est la matrice covariance exponentielle carrée caractérisant ainsi la non-linéarité dans l’espace latent X :
![]()
Enfin, les paramètres X,θ,σ^2 sont estimés par maximation de la vraisemblance via la descente de gradient stochastique :
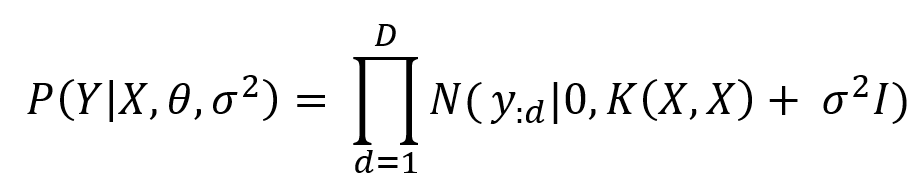
K étant la fonction de covariance exponentielle du PG et θ le vecteur contenant ses hyperparamètres θ ={α ,γ_1,γ_2…….γ_q}.
Une fois l’apprentissage accompli, l’espace latent capture la structure des pipelines « type de modèle, hyperparamètres… ». Nous pouvons voir celui-ci dans une représentation a 2 dimensions ou 5000 pipelines entrainés sur 576 jeux de données de référence OpenML, avec le coloris représentant la performance du métrique AURC :
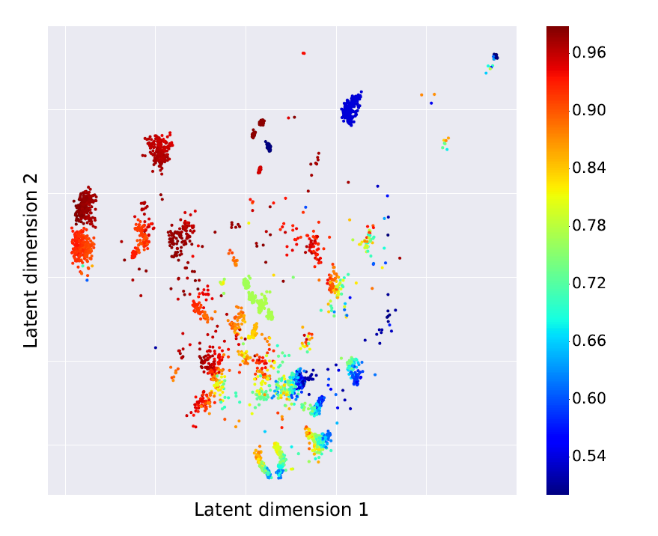
Muni des paramètres inférés par le GP-LVM, ces derniers sont ensuite utilisés pour estimer la performance y_(m,d)^* d’un pipeline m sur un nouveau jeu de donnée d avec les formules prédictives standard d’une régression par PG, produisant ainsi u_(m,d ),v_(m,d), où u_(m,d ) est l’estimé et v_(m,d) la distribution a posteriori qui caractérise l’incertitude de l’estimé.
4. Enfin, la dernière étape consiste à choisir de façon intelligente le prochain pipeline p_(n+1) à évaluer. Muni de l’estimé u_(m,d ), et l’incertitude produite par le biais de la distribution a posteriori v_(m,d), une fonction utilitaire dite fonction d’acquisition « Expected Improvement » (EI) dirige l’échantillonnage du prochain pipeline vers les zones où une amélioration par rapport à la meilleure performance obtenue jusqu’à présent est probable. Une fois l’EI calculé pour chaque pipeline, le prochain pipeline à évaluer sera donc le point où l’EI atteint son maximum.
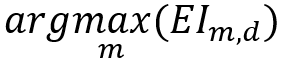
3 – Démonstration
Afin de démontrer l’usage de la fonctionnalité d’AutoML dans le service Azure Machine Learning, reprenons le même jeu de données d’un article que j’avais rédigé en 2014 sur le service Azure Machine Learning : « Predict Wine Quality With Azure ML ».
Contrairement à Azure ML qui propose un outil visuel dans le Cloud pour entrainer, créer et déployer un modèle, nous travaillerons dans cet article On Premise dans SQL Server et en mode « Code First » mais simplifié puisque les différents modèles seront entrainés et comparé pour moi.
Rappel du jeu de données :
– Il a été recueilli par Paulo Cortez, Antonio Cerdeira, Fernando Almeida, Telmo Matos et Jose Reis en 2009 pour la rédaction du livre : Modeling wine preferences by data mining from physicochemical properties. Citation for use: P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.
– Les échantillons proviennent de vins blancs et rouges du Portugal : Vinho Verde.
– Les données sont publiques, vous pourriez donc reproduire ces expérimentations : http://www3.dsi.uminho.pt/pcortez/wine/winequality.zip.
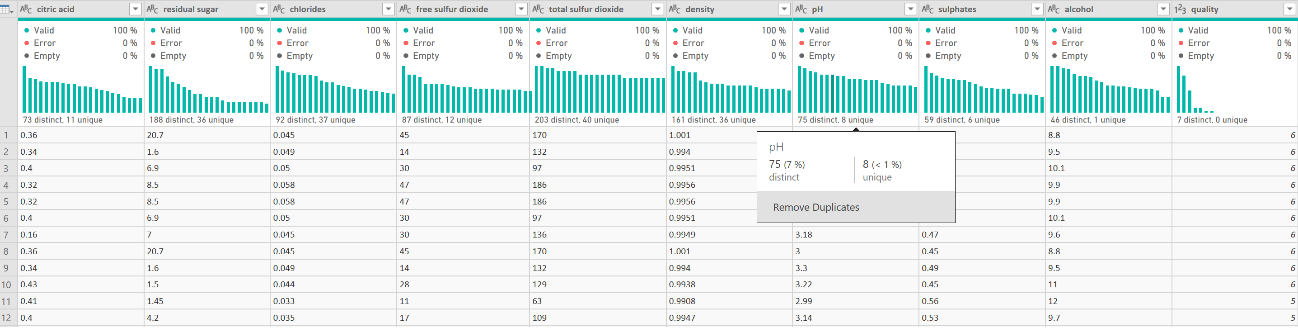
L’output dans notre exemple sera la qualité. Cette dernière est basée sur des données sensorielles médianes d’au moins 3 évaluations faites par des experts en vin. Chaque expert a classé la qualité du vin entre 0 (très mauvaise) et 10 (excellente). Le nombre de vins testés est de 1599 pour les rouges et de 4898 pour les blancs.
Avant de commencer cet expérimentation, revenons sur ce que nous souhaitons obtenir :
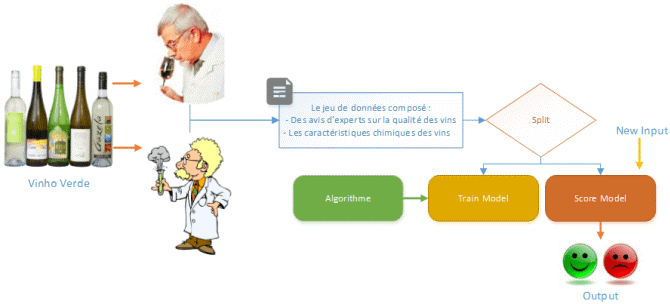
SQL Server 2017 et 2019 peuvent appeler l’apprentissage automatique automatisé Azure ML pour créer des modèles à partir de données SQL Server. Pour cela nous utiliserons la procédure stockée sp_execute_external_script permettant d’appeler des scripts Python.
Remarque : SQL Server 2017 et SQL Server 2019 peuvent être exécutés sous Windows ou Linux. Toutefois, cette intégration n’est pas disponible pour SQL Server 2017 sous Linux.
1. Après avoir installé SQL Server 2017 dans notre cas nous avons exécuté les scripts :
sp_configure 'external scripts enabled',1
reconfigure with override
2. La prochaine étape consiste à installer les bibliothèques d’apprentissage automatique en utilisant les commandes suivantes à partir de l’invite de commande en tant qu’administrateur après avoir arrêté le service SQL Server :
cd "C:\Program Files\Microsoft SQL Server"
cd "MSSQL14.ROMAINCA\PYTHON_SERVICES"
python.exe -m pip install azureml-sdk[automl]
python.exe -m pip install --upgrade numpy
python.exe -m pip install --upgrade sklearn
Remarque : Du fait des dépendances et des versions installées sur votre machine, des erreurs peuvent se produire lors de l’installation, pour corriger la plupart d’entre elles exécuter en tant qu’administrateur la commande suivante depuis le répertoire « PYTHON_SERVICES » : “python.exe -m pip install azureml-sdk[automl] –ignore-installed”. Cela va installer le SDK AzureML dont le module AutoML fait partie. Nous en profitons pour mettre à jour les module numpy et scikit-learn.
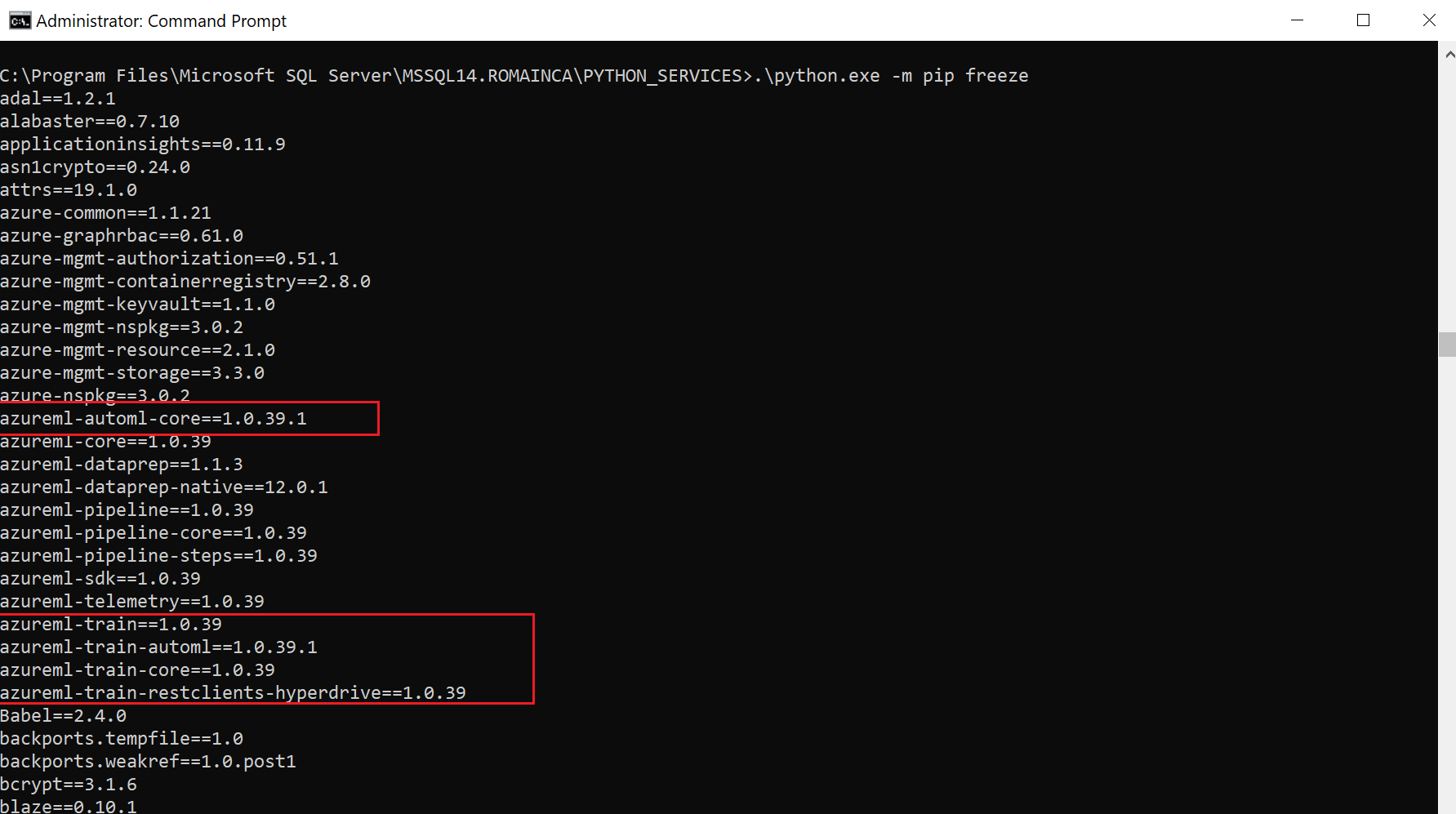
3. Pour vérifier l’installation, exécuter en tant qu’administrateur la commande suivante depuis le répertoire « PYTHON_SERVICES » : “python -m pip freeze”
4. Démarrez SQL Server et le service « Service SQL Server Launchpad ».
5. Dans le Pare-feu Windows, cliquez sur Paramètres avancés et dans Règles sortantes, désactivez « Bloquer l’accès réseau pour les comptes d’utilisateur locaux R dans l’instance SQL Server xxxx ».
6. Créez un espace de travail le service Azure Machine Learning. Vous pouvez utiliser les instructions à l’adresse suivante : https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-manage-workspace
7. Créez un fichier de fichier config.json à l’aide de l’ID d’abonnement, du nom du groupe de ressources et du nom de l’espace de travail utilisé pour créer l’espace de travail. Le fichier est décrit à l’adresse suivante: https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-configure-environment#workspace
{
"appId": "63fa98a3-1dfb-###-981c-5279f18df087",
"displayName": "principlename",
"name": "http://principlename",
"password": "###",
"tenant": "72f988bf-####-41af-91ab-2d7cd011db47"
}
8. Créez un principal de service Azure. Depuis Azure CLI (outil en ligne de commande pour la gestion des ressources Azure). Vous pouvez le faire avec les commandes:
az login
az account set --subscription subscriptionid
az ad sp create-for-rbac --name principlename --password password
9. Créer la base de données de test « automl », et exécutez les script TSQL « aml_model.sql », « aml_connection.sql », « AutoMLGetMetrics.sql », « AutoMLPredict.sql » et « AutoMLTrain.sql » disponible à l’adresse suivante : Github automated-machine-learning
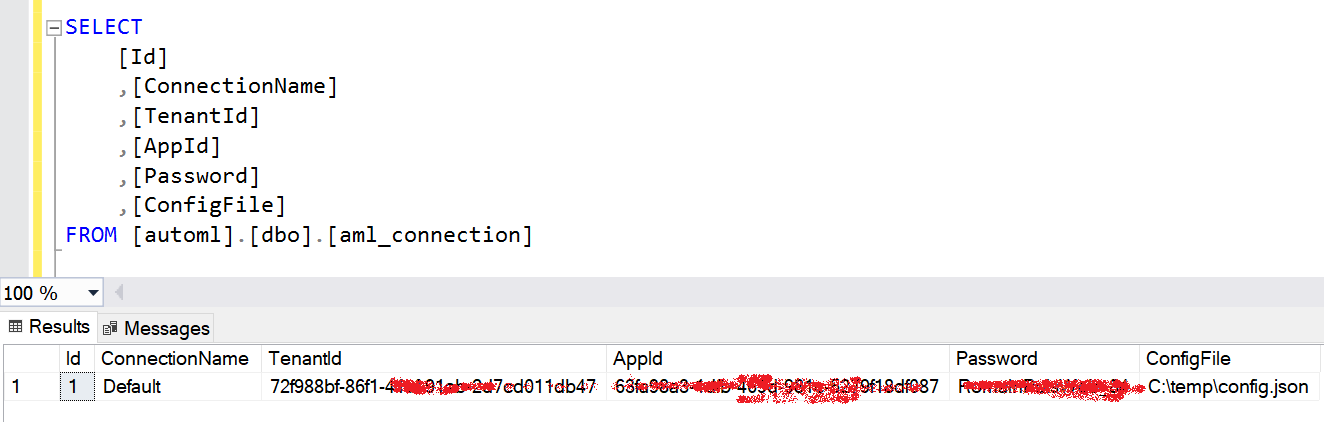
10. Insérez les valeurs , et ci-dessus dans la table aml_connection et renseignez le chemin absolu de votre fichier config.json. Définissez le nom sur «Default» :
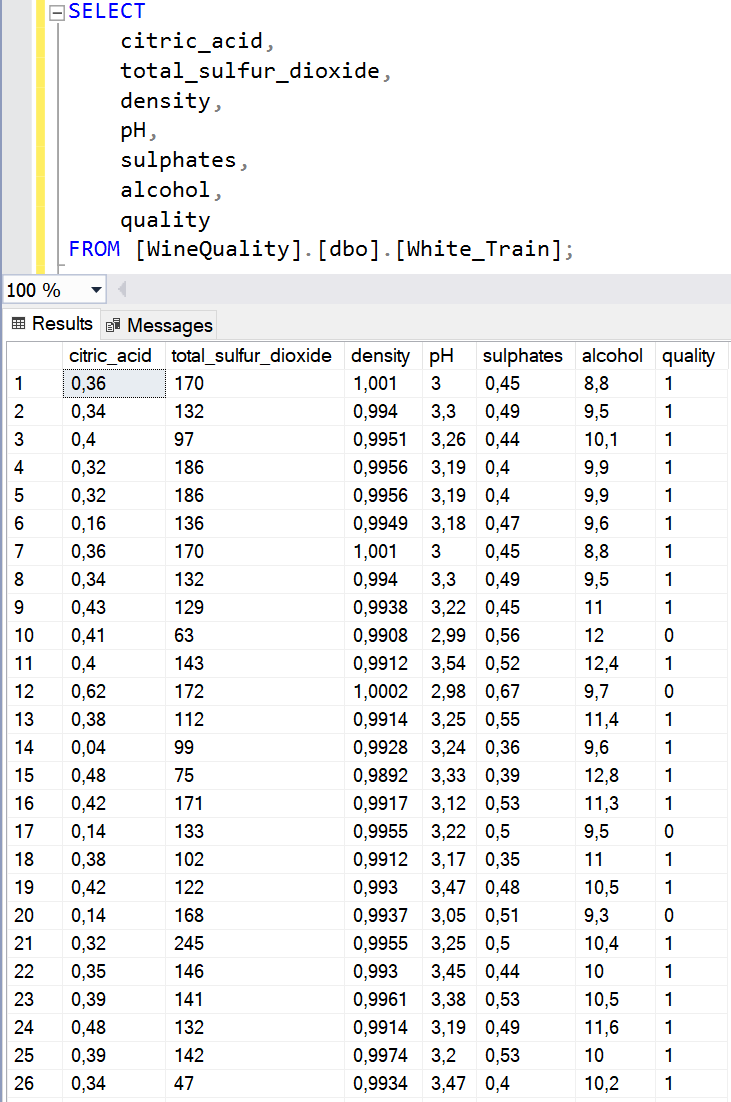
Le jeu de données que nous souhaitons prédire est disponible dans le backup de la base de donnés « WineQuality ».
Nous allons entrainer le modèle ML à partir de la table « White_Train » de la base de données « WineQuality ». Sur les 4898 lignes « white », la table « White_Train » en a 3675 (environ 75%) et la table « White_Test » en a 1223 (environ 25%) :
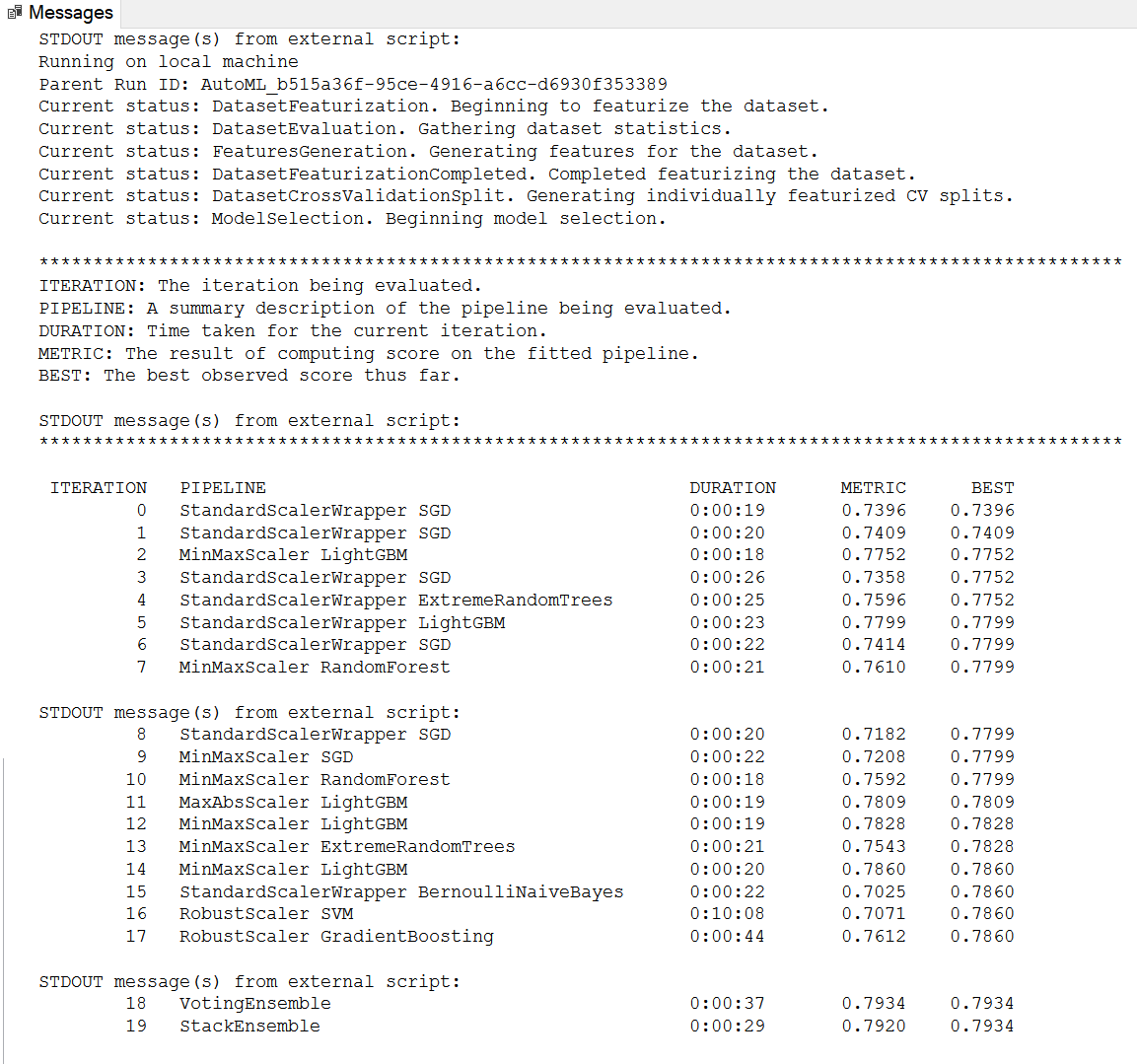
La requête suivante va insérer dans la table « aml_model », le modèle maximisant la métrique AUC_weighted :
INSERT INTO dbo.aml_model(RunId, ExperimentName, Model, LogFileText, WorkspaceName)
EXEC dbo.AutoMLTrain @input_query='
SELECT citric_acid, total_sulfur_dioxide, density, pH, sulphates, alcohol, quality FROM [WineQuality].[dbo].[White_Train] ',
@label_column = 'quality',
@iterations=20,
@experiment_name='automl-sql-wine',
@iteration_timeout_minutes=10
Remarque : AUC_weighted ou l’AUC pondéré en Français est ici utilisé compte-tenu de la modalité de la variable prédictive non équilibrée, on surmonte alors cet écueil en choisissant l’AUC pondéré. Contrairement à l’AUC qui somme l’aire sous la courbe avec des poids égaux, nous voulons donner plus d’importance à l’aire située près du haut du graphique. L’AUC pondéré crée donc un vecteur de pondération asymétrique en répartissant d’avantage le poids vers le haut de la courbe ROC. Mais voici la liste des métriques supportés : https://docs.microsoft.com/en-us/azure/machine-learning/service/concept-automated-ml#training-metric-output
Le nombre maximum de pipelines d’entrainement est ici configuré a 20 et chacune d’entre elles ne doit pas excéder 10 minutes.
La requête suivante permet d’avoir les métriques sur les modèles :
DECLARE @RunId NVARCHAR(43);
DECLARE @ExperimentName NVARCHAR(255);
SELECT TOP 1
@ExperimentName=ExperimentName,
@RunId=SUBSTRING(RunId, 1, 43)
FROM dbo.aml_model
ORDER BY CreatedDate DESC
EXEC dbo.AutoMLGetMetrics @RunId, @ExperimentName
Les modèles les plus pertinents ont été pour chaque exécution sauvegardés dans la table « aml_model » :
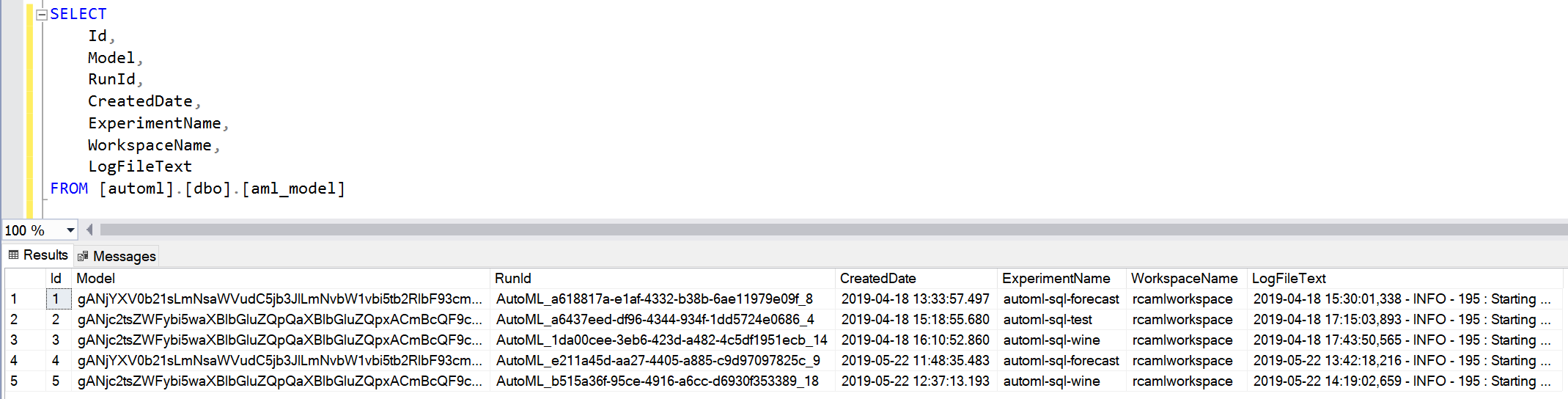
Du côté du service Azure Machine Learning, il est possible de suivre l’exécution des entrainements, le détail des exécutions, une liste complète des modèles créés et des informations sur leurs pertinences :
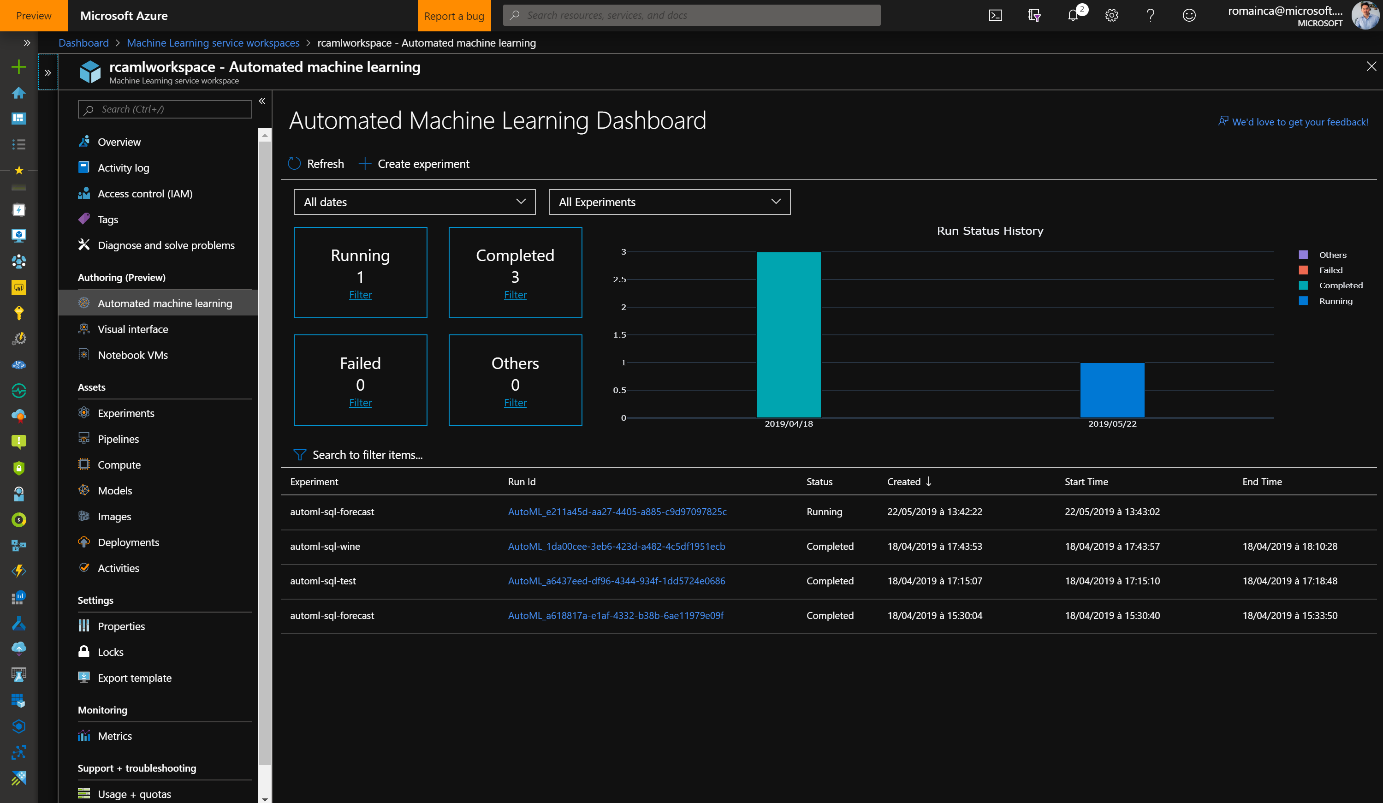
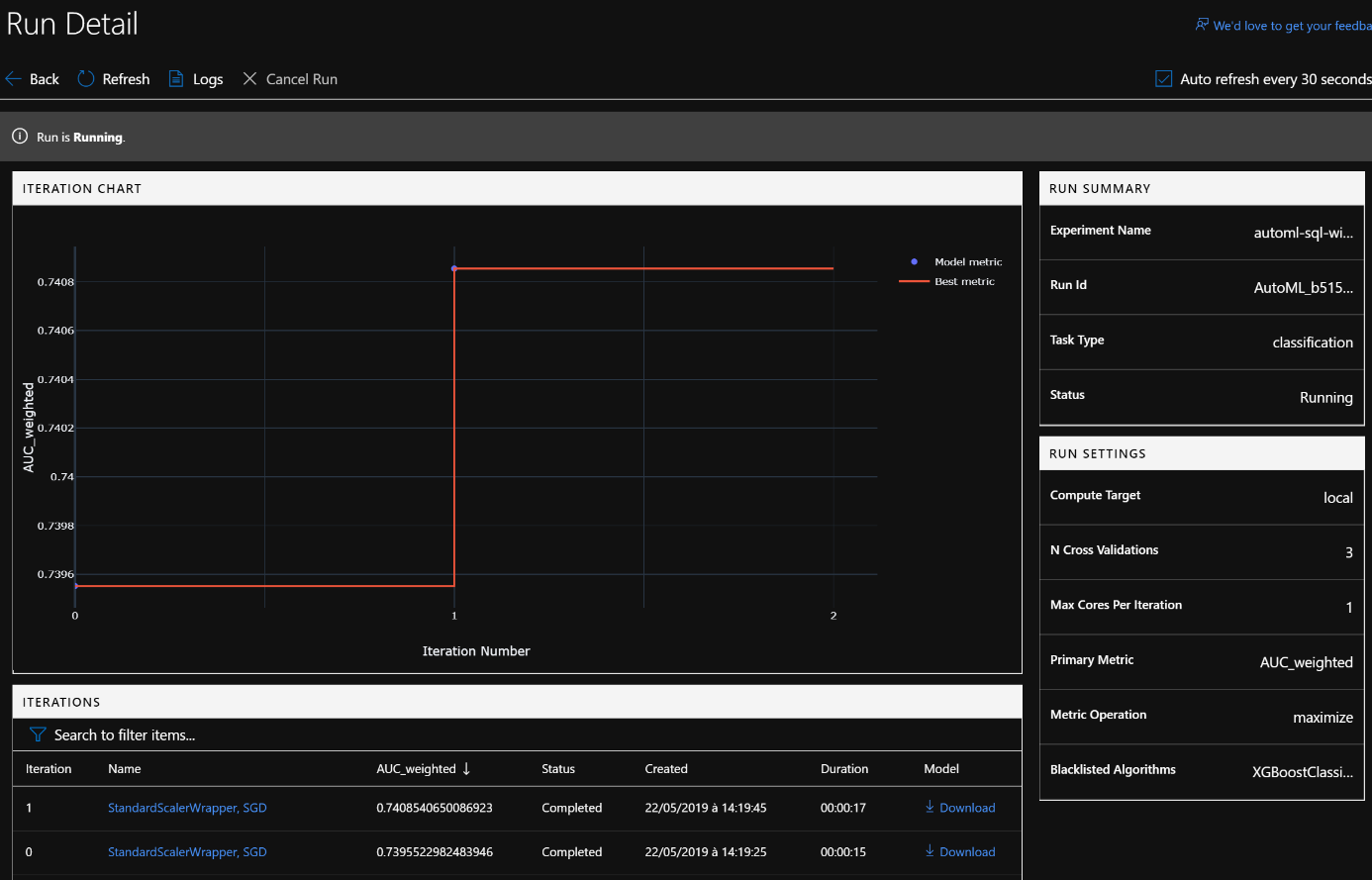
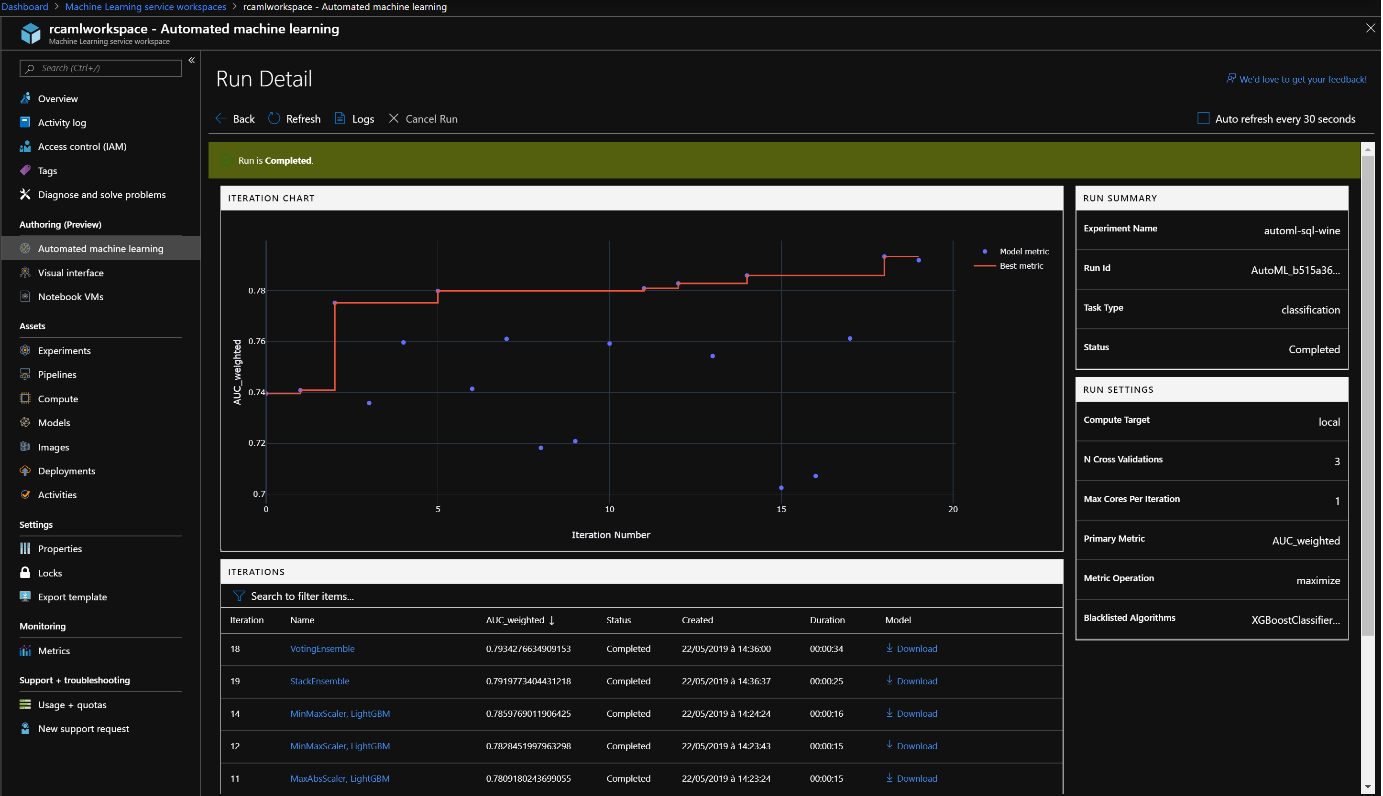
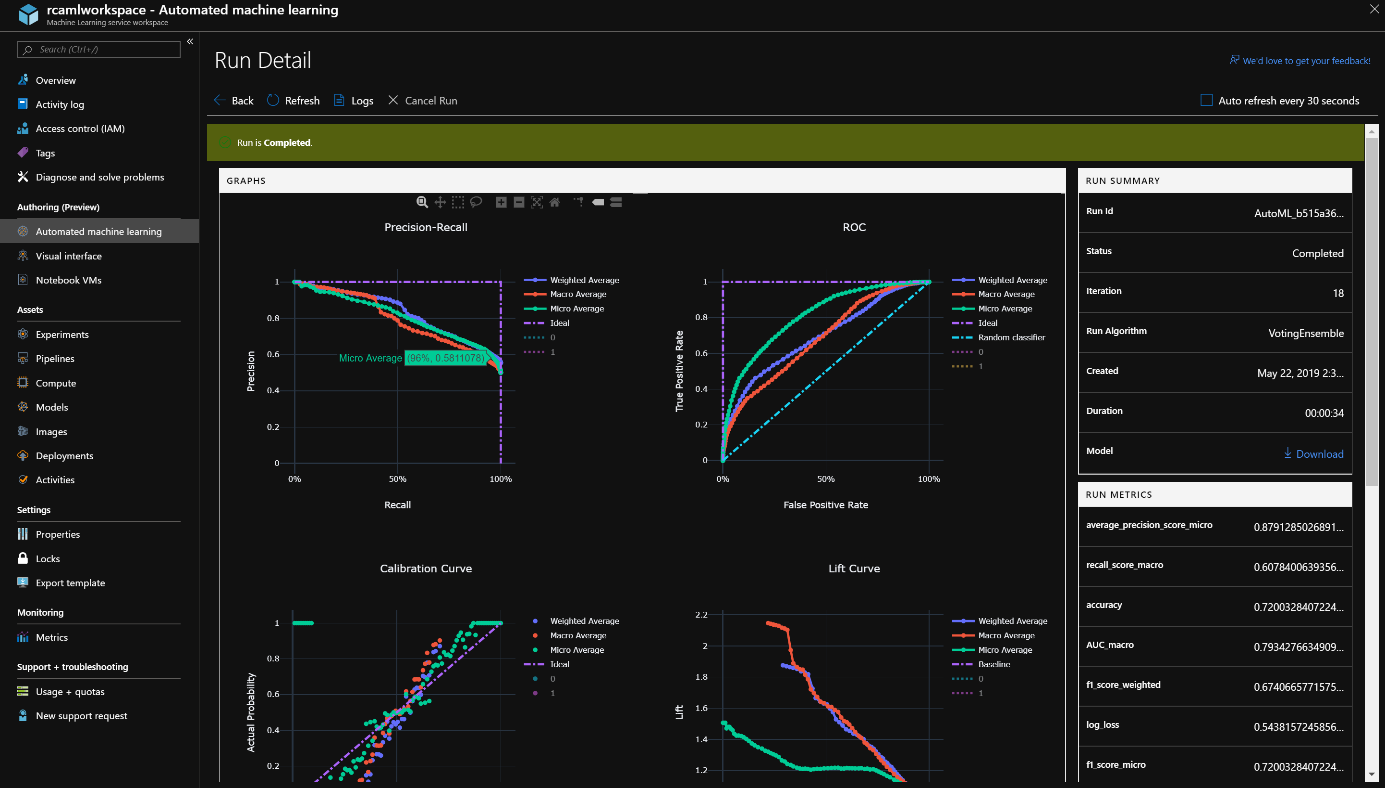
Plus d’information sur les graphiques disponibles : https://docs.microsoft.com/fr-fr/azure/machine-learning/service/how-to-track-experiments#understanding-automated-ml-charts
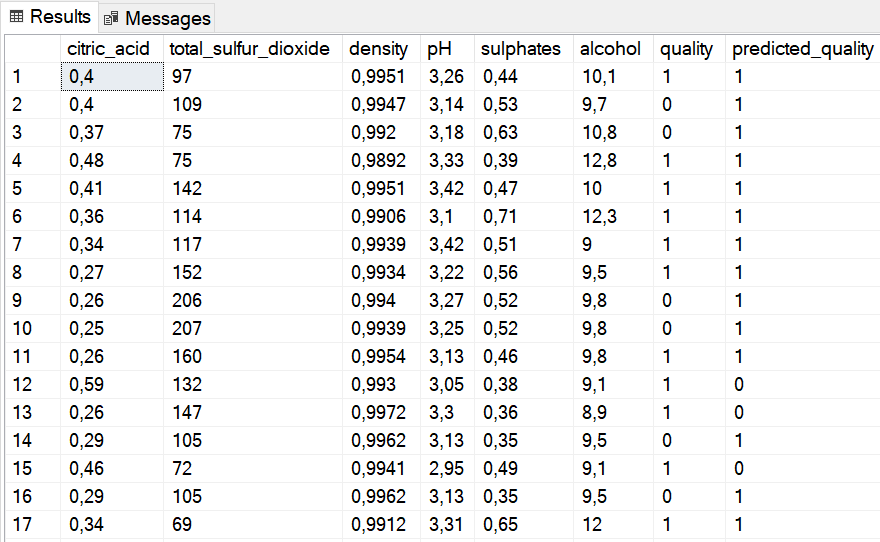
Pour effectuer des prédictions à partir de mon modèle, rien de plus simple :
DECLARE @Model NVARCHAR(MAX) = (
SELECT TOP 1 Model FROM dbo.aml_model
WHERE ExperimentName = 'automl-sql-wine'
ORDER BY CreatedDate DESC
)
EXEC dbo.AutoMLPredict @input_query='
SELECT citric_acid, total_sulfur_dioxide, density, pH, sulphates, alcohol, quality FROM [WineQuality].[dbo].[White_Test]',
@label_column='quality',
@model=@model
WITH RESULT SETS ((citric_acid FLOAT, total_sulfur_dioxide FLOAT, density FLOAT, pH FLOAT, sulphates FLOAT, alcohol FLOAT, quality INT, predicted_quality INT))
4 – Conclusion
Dans la démonstration précédente, nous avons vu la simplicité d’accès au service Automated Machine Learning depuis des scripts Python afin d’entrainer et sauvegarder un modèle dans une table le tout sans quitter SSMS !
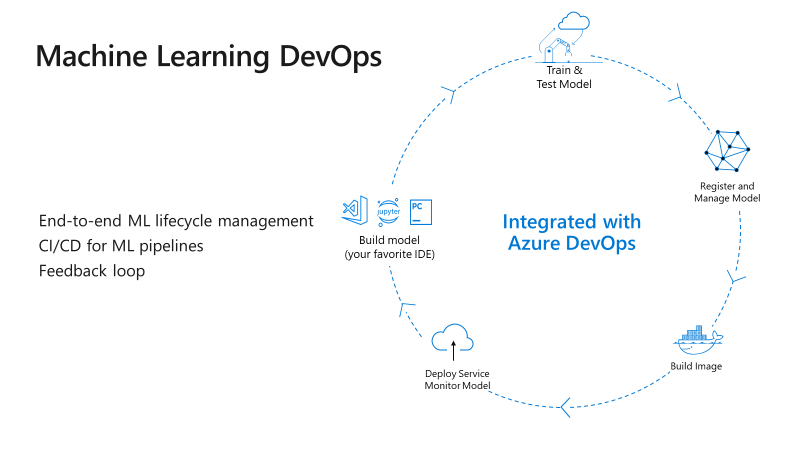
La fonctionnalité d’AutoML dans le service Azure Machine Learning facilite grandement la création et l’optimisation de modèle ML. De plus il s’intègre complètement dans la démarche DevOps :
Le service ne cesse d’évoluer (nouvelle interface en Preview, Time series forecasting, , export de modèle en format ONNX , …) : https://azure.microsoft.com/fr-fr/blog/a-look-at-azure-automated-machine-learning-capabilities/
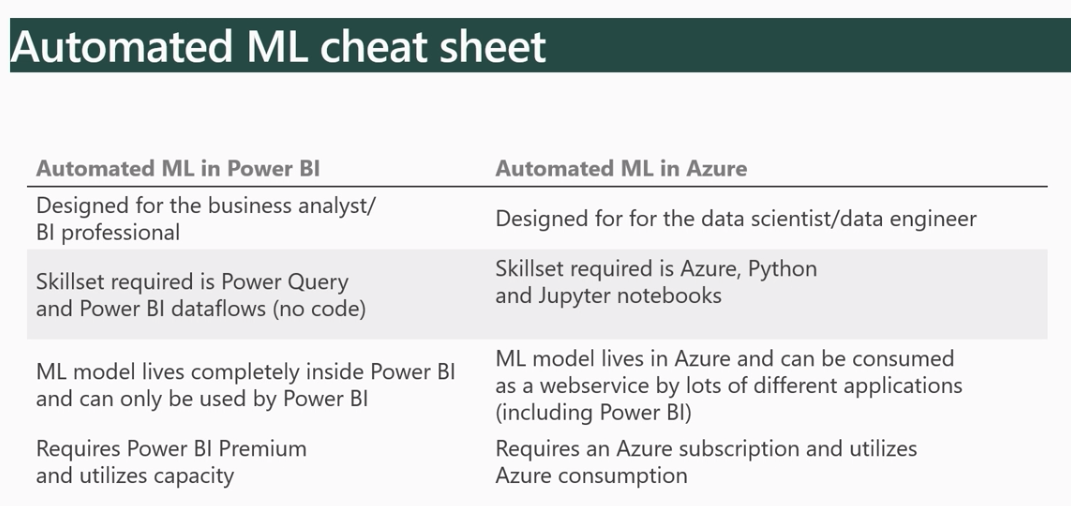
Nous prévoyons de rédiger une deuxième partie à cet article qui portera sur l’interprétabilité et l’opérationnalisation de ce même modèle. Un troisième article concernera l’AutoML dans Power BI à partir du même jeu de données, en attendant, voici une petite comparaison :